¿Qué es PyUMLGraph?
PyUMLGraph, como ya dije, no es más que un paquete (que contiene un comando) que permite hacerle ingeniería inversa al código de Python para obtener diagramas de clase que se asemejen a los de UML. Hasta ahora lo que se obtiene es solo los aspectos visuales del diagrama y no el formato UML en sí. De hecho, todo parece indicar que por ahora los formatos que se pueden utilizar son PNG, GIF, SVG, SVGZ, PostScript, XFIG, MIF (i.e. FrameMaker), los ficheros HPGL y PCL utilizados por los plotters e impresoras láser de la compañía HP, diagramas de GTK+, mapas de imágenes para servidores web y para clientes (X)HTML, y en la mayoría de los casos también otros formatos (la lista es MUY larga ;^) como JPEG, PDF, PIC, VML, VRML y bitmaps.
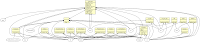
Para ser más precisos, si queremos obtener un diagrama que muestre en un color amarillo claro (#FFFFCC) los atributos y métodos de las clases del módulo estándar unittest entonces una manera muy sencilla de hacerlo es ejecutando el siguiente comando:
$ pyumlgraph.py --all --nodefillcolor=#FFFFCC --bgcolor white -o ~/Desktop/unittest.graph /usr/lib/python2.5/unittest.py
Así se obtendría un gráfico como el siguiente ( ver con más detalle ) :
Un poco de historia
Desde el punto de vista cronológico el surgimiento del paquete se remonta apróximadamente al año 2003 . En sus orígenes fue el embrión de un intento para reproducir la funcionalidad que ya ofrecía UMLGraph para representar el código de Java. Este último es un proyecto mucho más abarcador y muchísimo más activo. De echo fue toda una Odisea encontrar el código de la versión 0.1.10 de PyUMLGraph y hasta ahora no he logrado saber si hay otras más recientes. Todo apunta a que está abandonado su desarrollo. Pero a pesar de estar en fase de gestación, tiene un diseño modular y características notables. Mejorar estos aspectos y adicionar otros, es solo cuestión de tiempo. Además la idea subyacente es simplemente genial ...
¿Cómo funciona PyUMLGraph?
Una de las primeras tareas que tiene que enfrentar este módulo es la de descubrir las clases, sus elementos y establecer relaciones entre ellas. Hay dos enfoques principales para abordar este tema. El primero consiste en realizar un análisis sintáctico del código Python y, a partir de los resultados, generar el diagrama.
La segunda es la que utiliza PyUMLGraph y consiste en tracear o emular la ejecución del código e incorporar las funciones y clases a medida que se vayan llamando. Al final (y esta es una de las características más importantes del lenguaje) en Python la declaración de una clase o función es también una instrucción y todo se va creando en tiempo de ejecución. Es por esto que estamos ante un comportamiento más parecido al del depurador de Python que al de un analizador sintáctico. De hecho, básicamente tanto el depurador de Python como el depurador de PyDev, como PyUMLGraph hacen exactamente la misma cosa : monitorean la ejecución de un programa. Las únicas diferencias residen en la manera en que reaccionan. En el primer caso, al encontrar un punto de ruptura (en inglés breakpoint) se interrumpe la ejecución del script y se lanza una interfaz de ejecución de comandos en modo texto para continuar paso a paso, ver el estado del programa, los valores de las variables locales y globales, y el millón de cosas que se puede hacer con el depurador. En el segundo caso ocurre algo muy parecido, solo que la interfaz se encuentra en varias pestañas del IDE Eclipse. Finalmente la tarea de PyUMLGraph consiste en monitorear las llamadas que se van sucediendo e ir creando un catálogo de clases y funciones. A partir de esta información se obtienen todos los restantes datos que se necsitan y se genera posteriormente el diagrama en cuestión.
Algo que también es preciso resaltar es la facilidad con la que se logra todo esto. ¡Compruébelo Usted mismo!
# Fragmentos relevantes del código de PyUMLGraph
# para monitorear la ejecución del programa objetivo.
class InfoCollector:
def collectInfoYes(self):
sys.settrace(self.globalTrace)
def collectInfoNo(self):
sys.settrace(None)
def globalTrace(self, frame, event, arg):
"private"
if event == "call":
self.collectInfo(frame, event, arg)
return self.localTrace
def localTrace(self, frame, event, arg):
"private"
if event == "return":
className, functionName = self.getClassAndFunctionName(frame)
locals = frame.f_locals
globals = frame.f_globals
self.collectInfo(frame, event, arg)
Mis aportes
Si se preguntan cuales fueron mis aportes, aquí les enumero los que voy recordando (sí ... me estoy poniendo viejo XD ) :
- Contabilizar en el modelo a los descriptores. Anteriormente la presencia
de métodos estáticos en una clase, por ejemplo, hacía que fracasará la
ejecución del comando.
- Utilizar el módulo optparse en vez de getopt.
- Arreglar un defecto que impedía que muchas clases no fueran detectadas en
casos especiales (por ejemplo, con el módulo trac.core el diagrama quedaba
vacío).
- Incorporar la capacidad de filtrar los elementos del diagrama.
- Cambiar el nombre de varias opciones para que sean compatibles con los
estándares.
- Una nueva opción para mostrar en el diagrama solamente las clases de módulos
especificados como parámetros.
- Mostrar los parámetros de los métodos junto con los tipos inferidos en
tiempo de ejecución.
- Añadir varios niveles de registro de eventos.
... en fin, nuevos bríos :). Por ahora el comando luce más o menos así :
$ pyumlgraph.py --help
Usage: pyumlgraph.py [OPTIONS] <Python program> [ARGS]
Options:
--version show program's version number and exit
-h, --help show this help message and exit
Diagram settings:
--methods Show class methods.
--attributes Show class attributes.
--all Equivalent to --types --methods --attributes
--references.
--references Distinguish between self and local references.
Color & styles:
--node-fill-color=COLOR
Set the node fill color to this string.COLOR can be
Unix color name or a hex 3-tuple.
--bgcolor=COLOR Set the diagram's background color to this
string.COLOR can be Unix color name or a hex 3-tuple.
Files & Directories:
-o FILE, --output-file=FILE
write dot language UML output to this file.
Class filters:
--types Include common types (str, int, dict, etc.).
--include-modules=LIST
Consider only classes found in modules listed in LIST.
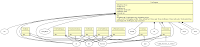
En el punto actual, el siguiente comando
$ pyumlgraph.py --all -v --node-fill-color=#FFFFCC -v --include-modules=unittest,__main__ -o ~/Desktop/unittest.dot /usr/lib/python2.5/unittest.py > ~/Desktop/unittest.log
... presentará el siguiente diagrama ( ver con más detalle )
Pero sucede que todavía hay muchas tareas por hacer, por ejemplo :
- Mejorar la visualización del diagrama, especialmente el solapamiento de las
relaciones de agregación por referencia y por valor.
- Mejorar el layout, a veces las líneas quedan muy cerca, afectándose la
legibilidad del modelo.
- Resolver el error que ocurre al confeccionar modelos a partir de paquetes
que utilizan pkg_resources.
- Otras de las que ni siquiera me he dado cuenta ;^)
Conclusiones
El módulo analizado es un ejemplo de las posibilidades y la sencillez de la metaprogramación e introspección que ofrece Python. Entre sus virtudes se encuentra su naturaleza modular y las posibilidades de generación hacia cualquier otro formato con gran facilidad. Quizás en este último aspecto se necesite un mínimo de trabajo todavía para que se agilice aún más esta tarea ;o).
Sin embargo todo no es color de rosa. Como se ejecuta íntegramente el código de la librería analizada, sucede que los tiempos de ejecución pueden resultar elevados. Además esto puede traer efectos colaterales (e.g. conexiones de red, acceso a ficheros y recursos, cambios en el sistema). Por esta razón y otras, puede suceder que no se cubran todas las partes del programa durante la ejecución. En estos casos hay elementos que quedarían fuera del diagrama. Además, como se interceptan determinadas funciones básicas, se suplanta a cualquier depurador que se esté utilizando. De todas formas hay algunos casos de uso interesantes que pueden ser muy útiles. Por tanto, simelo preguntan, les diría que PyUMLGraph es uno de esos softwares que ilumina el camino para crecer y acercarnos a un fin bien claro. Espero poder recorrerlo con Ustedes, los lectores, aquí en el blog de Simelo.












